
Podonos's independent benchmark confirms that the aurigin.ai audio deepfake detection model leads the field in terms of accuracy.
Podonos's independent benchmark confirms that the aurigin.ai audio deepfake detection model leads the field in terms of accuracy. Combined with the low compute requirements, our models are the first ones that pass the bar on both accuracy and infrastructure requirements: accurate enough to trust and cheap enough to run continuously on every call.
In short
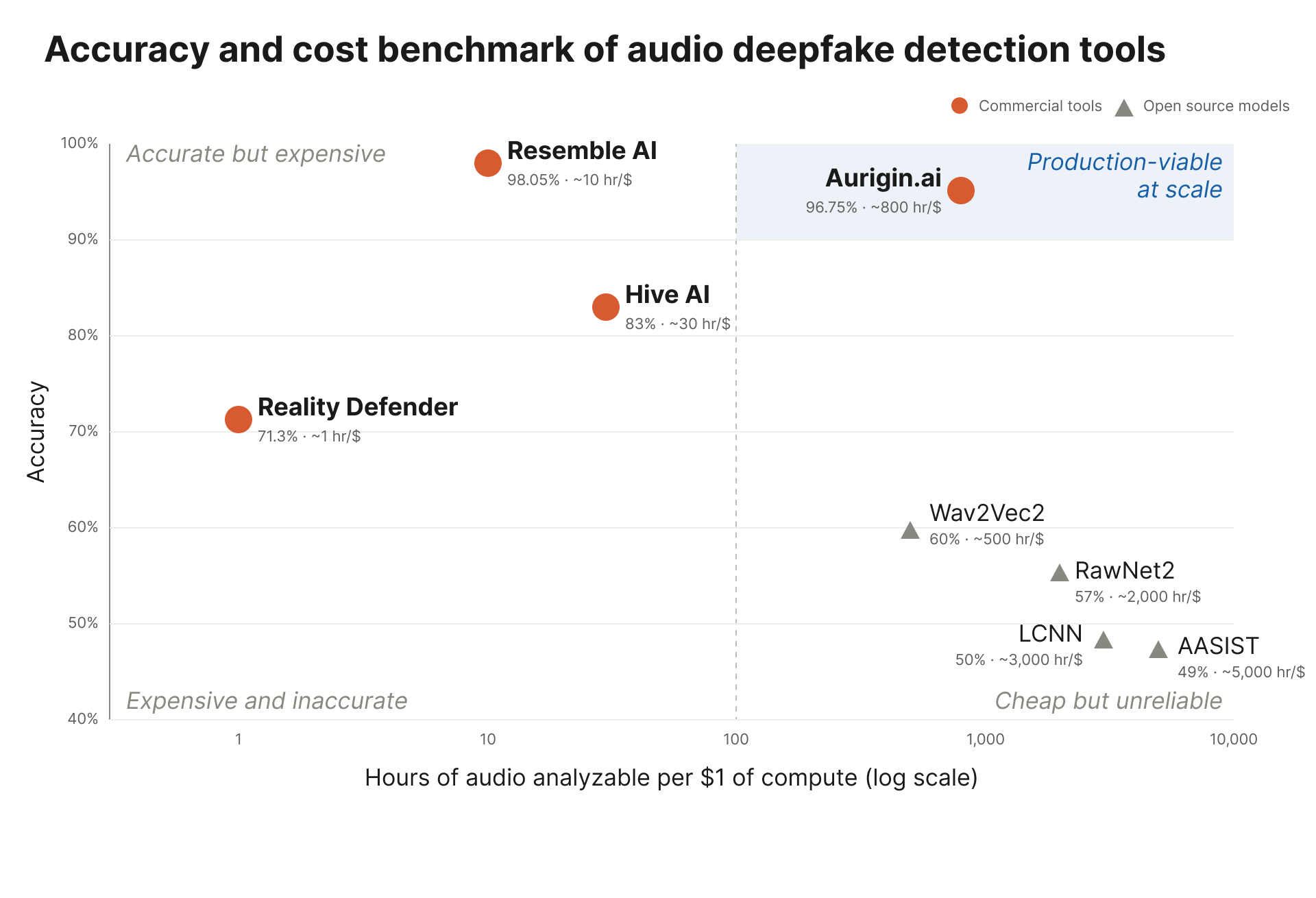
- 96.75% accuracy, F1 0.967, 1.5% false-positive rate on the first private-label audio deepfake detection benchmark (Podonos). Top accuracy tier, with the lowest wrongful-fake rate of any commercial detector evaluated.
- Infrastructure about 100x cheaper than the only other detector in the same accuracy tier. The first model that makes "screen every call" cost the same as "spot-check one-in-a-hundred" elsewhere. One cheap GPU ($0.50/h) of compute hardware can process up to 400 concurrent calls in real-time - less than $0.001 of infrastructure costs per hour of audio analyzed.
- The result: audio deepfake detection stops being a triage tool the security team reaches for after a human flags something, and starts being an always-on layer underneath every voice channel.
Two paths, neither of which worked
Until now, every buyer of audio deepfake detection has been routed into one of two compromises.
The accurate path - Until now, infrastructure costs were the main cost drivers for the high-end models. Resemble AI's 3-billion-parameter DETECT-3B Omni, Reality Defender's H100-class transformer - costs roughly $0.10 to several dollars per hour of audio analyzed. Even for a simple contact center deployment, that reaches very quickly tens or even hundreds of thousands of dollars per month in infrastructure costs. To make this economically viable, not the full length of calls can be analyzed. To make it economically viable, only a few seconds per call get analyzed or only validate calls that a human has already flagged - and despite still high infrastructure costs, one has to accept that any voice clone routed through the 99% of traffic you never deeply inspected has a clean path to its target.
The affordable path - the open-source detectors (Wav2Vec2, RawNet2, LCNN, AASIST) trained on ASVspoof 2019 - looks viable on paper and collapses in the field. Those models predate ElevenLabs, F5-TTS and Chatterbox. They were never trained on modern parametric codecs like Opus or the new generation of neural audio codecs (Encodec, SoundStream and their derivatives) that VoIP and AI-audio stacks now routinely use. They were not trained on phone-call audio with lossy transmission, packet loss, background voices, or the speaker walking through a busy office. Podonos quantified the collapse: all four standard open-source baselines score between 48% and 63% on its benchmark - barely better than random - with one of them simply predicting "fake" for every input. Cheap is not a path to coverage when the detector is wrong half the time.
This is the trade-off that has held audio deepfake detection back from becoming real security infrastructure. Pick accurate-and-spot-check, or affordable-and-broken. Either way, the calls you do not inspect are the calls the attacker takes.
We solved both sides at once
Aurigin.ai is the first audio deepfake detection model that clears both bars. 96.75% accuracy on the Podonos benchmark, top tier alongside Resemble's 3B model and more than 13 percentage points ahead of every other commercial vendor evaluated. And it runs at a sub-cent per hour of audio - 400 concurrent hour-long streams analyzed in real time for about $0.50 in hardware, on a chip you can hold in your hand.
The chart above shows what that combination means. The upper-right quadrant - production-grade accuracy paired with the compute economics to scale - has exactly one occupant. The other production-grade detectors in our accuracy tier sits at roughly 100x the cost per hour, structurally fine to vet a flagged call but cost-prohibitive across an entire audio surface. The open-source baselines are cheap but not reliable in real-world scenarios. We are the only point on the chart an enterprise security architect can actually deploy across their entire audio surface.
The accomplishment is not the accuracy number alone. It is 96.75% accuracy in a 300M-parameter model that runs even on a single CPU (e.g., on a Raspberry PI).
Audio communication finally gets its spam-filter moment
Email went through this transition in the 2000s. Before automated spam filtering, screening suspicious mail was a human responsibility: the receptionist sorting the post, the analyst reviewing flagged messages. After it, spam filtering became ambient. It runs on every inbound email, in the background, without anyone clicking "scan this one." Nobody now operates a corporate inbox that requires manual triage of suspicion.
Voice communication has been stuck in the pre-spam-filter era. The first line of defense against voice cloning has been the listener noticing that something feels off and escalating to someone with detection tools. That is, structurally, the worst possible defense against social engineering - because social engineering's entire mechanism is to short-circuit the listener's "this feels off" instinct. Urgency. Authority. Familial familiarity. The fake CFO who needs the wire moved before market close. The cloned voice of a child saying they have been in an accident. These attacks land because the human gate fails on exactly the calls the attacker engineered it to fail on. Asking the target to be the detector is asking the wrong thing of the wrong person at the worst possible moment.
Removing that gate is the real outcome of this benchmark. When deepfake detection is accurate enough to act on automatically and cheap enough to run on every call, voice security becomes a passive layer underneath every channel - the same way TLS sits underneath every HTTPS connection or spam filtering underneath every inbox. The listener no longer has to be the first line of defense. The detection runs anyway. The fraud or compliance team only sees the small subset of calls that actually warrant their attention, because everything else has already been screened in the background.
That changes the questions an organization gets to ask:
- A TelCo can run real-time scam filters and robocall detection on every call across its network, treating cloned voices as a fraud signal alongside the heuristics it already uses - without sampling, without per-call budget, without choosing which subscribers' traffic to inspect.
- A contact center or help desk can route every customer call through real-time voice cloning detection before authentication or any transaction step. Agents handle the calls that pass silently; the flagged ones escalate.
- A bank can screen every KYC call, every relationship-manager interaction, every wire-instruction call - rather than only the ones a fraud team has already flagged through a process attackers are explicitly trying to deceive.
- An enterprise can actively monitor the trust boundary in all voice channels (Teams, Zoom, Webex, recorded internal meetings) in the same way it treats its email as spam-filtered by default. Biometric-bypass attempts and synthetic-voice impersonations get caught as a matter of baseline, not as the outcome of someone happening to notice.
- A platform or newsroom can process every uploaded audio clip rather than triaging a queue. The default becomes "verified," and only items that fail verification surface.
The economic point underneath all of these is the same. At a tenth of a cent of infrastructure costs per hour of audio, putting real-time deepfake detection on an entire enterprise voice channel does not require half a data center anymore. Procurement stops asking "what are the cost implications on IT infrastructure" and starts asking "is there any reason we'd not screen everything." The answer, for the first time, is no.
How we got here
The benchmark settles a question the industry has been arguing for two years: does the most accurate audio deepfake detection model have to be the largest one? Resemble's leaderboard position and the broader pattern of scale-driven dominance in vision and language modeling pointed at yes. The standard playbook would have been to keep growing the model. We did not, because we knew the operational consequence: a detector that needs a datacenter GPU per stream is a detector customers will quietly stop running on most of their traffic.
Instead, we treated parameter count as a hard ceiling and pushed every other lever inside it - architecture choices, training-data composition, augmentation strategy, robustness to the messy real-world conditions audio actually arrives in. Compressed through neural codecs. Resampled at unusual rates. Transported across packet-lossy phone connections. Captured in environments with overlapping speech and background noise. Each of those is a training-distribution decision, not a model-size decision. The Podonos result, in a real sense, is a result about that methodology being the right one.
For our customers, the practical effect is simple. The most accurate audio deepfake detection model on the market - independently confirmed - is also the only one in that accuracy tier they can afford to deploy across their entire audio surface. Voice cloning detection, biometric-bypass prevention, scam-call and robocall screening - these stop being premium features applied to a triaged subset and become baseline infrastructure. That is the new normal for enterprise communication security: not a tool you point at specific calls, but a layer that runs underneath all of them.
Run your own benchmark
Independent benchmarks are a strong starting point and save a lot of evaluation time, but accuracy on a general test set is not the same as accuracy on your specific data. Feel free to assess your perceived accuracy for your use case: You can process your test set easily through our API. API keys and a quick-start guide are available at app.aurigin.ai.